|
|



|
Le processeur (CPU, pour Central Processing Unit, soit Unité Centrale de Traitement) est le cerveau de l'ordinateur. Il permet de manipuler des informations numériques, c'est-à-dire des informations codées sous forme binaire, et d'exécuter les instructions stockées en mémoire. Le premier microprocesseur (Intel 4004) a été inventé en 1971. Il s'agissait d'une unité de calcul de 4 bits, cadencé à 108 kHz. Depuis, la puissance des microprocesseurs augmente exponentiellement. Quels sont donc ces petits morceaux de silicium qui dirigent nos ordinateurs?
Le processeur (noté CPU, pour Central Processing Unit) est un circuit électronique cadencé au rythme d'une horloge interne, grâce à un cristal de quartz qui, soumis à un courant électrique, envoie des impulsions, appelées « top ». La fréquence d'horloge (appelée également cycle, correspondant au nombre d'impulsions par seconde, s'exprime en Hertz (Hz). Ainsi, un ordinateur à 200 MHz possède une horloge envoyant 200 000 000 de battements par seconde. La fréquence d'horloge est généralement un multiple de la fréquence du système (FSB, Front-Side Bus), c'est-à-dire un multiple de la fréquence de la carte mère A chaque top d'horloge le processeur exécute une action, correspondant à une instruction ou une partie d'instruction. L'indicateur appelé CPI (Cycles Par Instruction) permet de représenter le nombre moyen de cycles dhorloge nécessaire à lexécution dune instruction sur un microprocesseur. La puissance du processeur peut ainsi être caractérisée par le nombre d'instructions qu'il est capable de traiter par seconde. L'unité utilisée est le MIPS (Millions d'Instructions Par Seconde) correspondant à la fréquence du processeur que divise le CPI.
Une instruction est l'opération élémentaire que le processeur peut accomplir. Les instructions sont stockées dans la mémoire principale, en vue d'être traitée par le processeur. Une instruction est composée de deux champs:
Le nombre d'octets d'une instruction est variable selon le type de donnée (l'ordre de grandeur est de 1 à 4 octets). Les instructions peuvent être classées en catégories dont les principales sont :
Lorsque le processeur exécute des instructions, les données sont temporairement stockées dans de petites mémoires rapides de 8, 16, 32 ou 64 bits que l'on appelle registres. Suivant le type de processeur le nombre global de registres peut varier d'une dizaine à plusieurs centaines. Les registres principaux sont:
La mémoire cache (également appelée antémémoire ou mémoire tampon) est une mémoire rapide permettant de réduire les délais d'attente des informations stockées en mémoire vive. En effet, la mémoire centrale de l'ordinateur possède une vitesse bien moins importante que le processeur. Il existe néanmoins des mémoires beaucoup plus rapides, mais dont le coût est très élevé. La solution consiste donc à inclure ce type de mémoire rapide à proximité du processeur et d'y stocker temporairement les principales données devant être traitées par le processeur. Les ordinateurs récents possèdent plusieurs niveaux de mémoire cache :
Les signaux de commande sont des signaux électriques permettant d'orchestrer les différentes unités du processeur participant à l'exécution d'une instruction. Les signaux de commandes sont distribués grâce à un élément appelé séquenceur. Le signal Read / Write, en français lecture / écriture, permet par exemple de signaler à la mémoire que le processeur désire lire ou écrire une information.
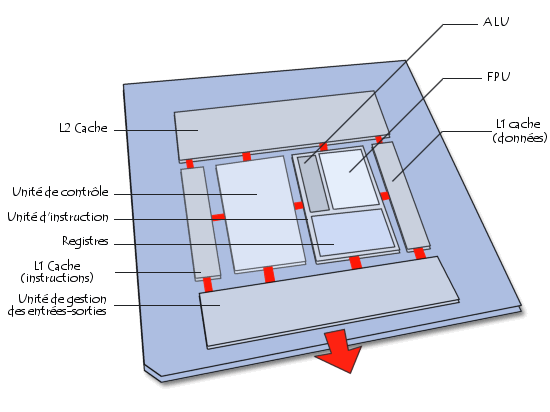
Le processeur est constitué d'un ensemble d'unités fonctionnelles reliées entre elles. L'architecture d'un microprocesseur est très variable d'une architecture à une autre, cependant les principaux éléments d'un microprocesseur sont les suivants :
Le schéma ci-dessous donne une représentation simplifiée des éléments constituant le processeur (l'organisation physique des éléments ne correspond pas à la réalité) :
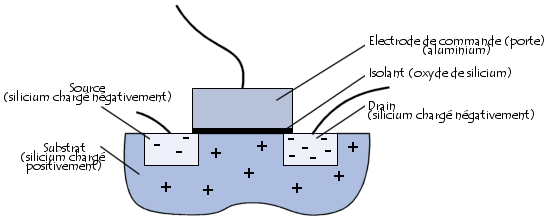
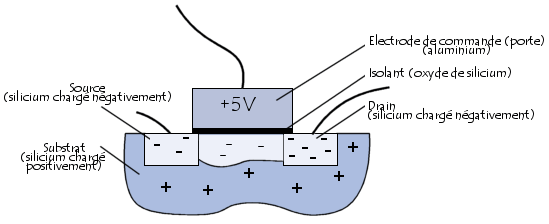
Pour effectuer le traitement de l'information, le microprocesseur possède un ensemble d'instructions, appelé « jeu d'instructions », réalisées grâce à des circuits électroniques. Plus exactement, le jeu d'instructions est réalisé à l'aide de semiconducteurs, « petits interrupteurs » utilisant l'effet transistor, découvert en 1947 par John Barden, Walter H. Brattain et William Shockley qui reçurent le prix Nobel en 1956 pour cette découverte. Un transistor (contraction de transfer resistor, en français résistance de transfert) est un composant électronique semi-conducteur, possédant trois électrodes, capable de modifier le courant qui le traverse à l'aide d'une de ses électrodes (appelée électrode de commande). On parle ainsi de «composant actif», par opposition aux « composants passifs », tels que la résistance ou le condensateur, ne possédant que deux électrodes (on parle de « bipolaire »). Le transistor MOS (métal, oxyde, silicium) est le type de transistor majoritairement utilisé pour la conception de circuits intégrés. Le transistor MOS est composé de deux zones chargées négativement, appelées respectivement source (possédant un potentiel quasi-nul) et drain (possédant un potentiel de 5V), séparées par une région chargée positivement, appelée substrat (en anglais substrate). Le substrat est surmonté d'une électrode de commande, appelée porte (en anglais gate, parfois également appelée grille), permettant d'appliquer une tension sur le substrat.
Lorsqu'aucune tension n'est appliquée à l'électrode de commande, le substrat chargé positivement agit telle une barrière et empêche les électrons d'aller de la source vers le drain. En revanche, lorsqu'une tension est appliquée à la porte, les charges positives du substrat sont repoussées et il s'établit un canal de communication, chargé négativement, reliant la source au drain.
Le transistor agit donc globalement comme un interrupteur programmable grâce à l'électrode de commande. Lorsqu'une tension est appliquée à l'électrode de commande, il agit comme un interrupteur fermé, dans le cas contraire comme un interrupteur ouvert.
Assemblés, les transistors peuvent constituer des circuits logiques, qui, assemblés à leur tour, constituent des processeurs. Le premier circuit intégré date de 1958 et a été mis au point par la société Texas Instruments. Les transistors MOS sont ainsi réalisés dans des tranches de silicium (appelées wafer, traduisez gaufres), obtenues après des traitements successifs. Ces tranches de silicium sont alors découpées en éléments rectangulaires, constituant ce que l'on appelle un « circuit ». Les circuits sont ensuite placés dans des boîtiers comportant des connecteurs d'entrée-sortie, le tout constituant un « circuit intégré ». La finesse de la gravure, exprimée en microns (micromètres, notés µm), définit le nombre de transistors par unité de surface. Il peut ainsi exister jusqu'à plusieurs millions de transistors sur un seul processeur. La loi de Moore, édictée en 1965 par Gordon E. Moore, cofondateur de la société Intel, prévoyait que les performances des processeurs (par extension le nombre de transistors intégrés sur silicium) doubleraient tous les 12 mois. Cette loi a été révisée en 1975, portant le nombre de mois à 18. La loi de Moore se vérifie encore aujourd'hui. Dans la mesure où le boîtier rectangulaire possède des broches d'entrée-sortie ressemblant à des pattes, le terme de « puce électronique » est couramment employé pour désigner les circuits intégrés.
Chaque type de processeur possède son propre jeu d'instruction. On distingue ainsi les familles de processeurs suivants, possédant chacun un jeu d'instruction qui leur est propre :
Cela explique qu'un programme réalisé pour un type de processeur ne puisse fonctionner directement sur un système possédant un autre type de processeur, à moins d'une traduction des instructions, appelée émulation. Le terme « émulateur » est utilisé pour désigner le programme réalisant cette traduction.
On appelle jeu dinstructions lensemble des opérations élémentaires qu'un processeur peut accomplir. Le jeu d'instruction d'un processeur détermine ainsi son architecture, sachant qu'une même architecture peut aboutir à des implémentations différentes selon les constructeurs. Le processeur travaille effectivement grâce à un nombre limité de fonctions, directement câblées sur les circuits électroniques. La plupart des opérations peuvent être réalisé à l'aide de fonctions basiques. Certaines architectures incluent néanmoins des fonctions évoluées courante dans le processeur.
L'architecture CISC (Complex Instruction Set Computer, soit « ordinateur à jeu d'instruction complexe ») consiste à câbler dans le processeur des instructions complexes, difficiles à créer à partir des instructions de base. L'architecture CISC est utilisée en particulier par les processeurs de type 80x86. Ce type d'architecture possède un coût élevé dû aux fonctions évoluées imprimées sur le silicium. D'autre part, les instructions sont de longueurs variables et peuvent parfois nécessiter plus d'un cycle d'horloge. Or, un processeur basé sur l'architecture CISC ne peut traîter qu'une instruction à la fois, d'où un temps d'exécution conséquent.
Un processeur utilisant la technologie RISC (Reduced Instruction Set Computer, soit « ordinateur à jeu d'instructions réduit ») n'a pas de fonctions évoluées câblées. Les programmes doivent ainsi être traduits en instructions simples, ce qui entraîne un développement plus difficile et/ou un compilateur plus puissant. Une telle architecture possède un coût de fabrication réduit par rapport aux processeurs CISC. De plus, les instructions, simples par nature, sont exécutées en un seul cycle d'horloge, ce qui rend l'exécution des programmes plus rapide qu'avec des processeurs basés sur une architecture CISC. Enfin, de tels processeurs sont capables de traîter plusieurs instructions simultanément en les traitant en parallèle.
Au cours des années, les constructeurs de microprocesseurs (appelés fondeurs), ont mis au point un certain nombre d'améliorations permettant d'optimiser le fonctionnement du processeur.
Le parallélisme consiste à exécuter simultanément, sur des processeurs différents, des instructions relatives à un même programme. Cela se traduit par le découpage d'un programme en plusieurs processus traités en parallèle afin de gagner en temps d'exécution. Ce type de technologie nécessite toutefois une synchronisation et une communication entre les différents processus, à la manière du découpage des tâches dans une entreprise : le travail est divisé en petits processus distincts, traités par des services différents. Le fonctionnement d'une telle entreprise peut être très perturbé lorsque la communication entre les services ne fonctionne pas correctement.
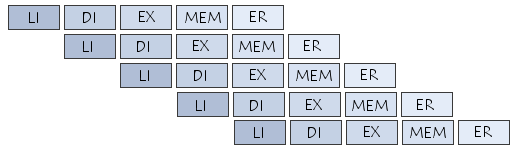
Le pipeline (ou pipelining) est une technologie visant à permettre une plus grande vitesse d'exécution des instructions en parallélisant des étapes. Pour comprendre le mécanisme du pipeline, il est nécessaire au préalable de comprendre les phases d'exécution d'une instruction. Les phases d'exécution d'une instruction pour un processeur contenant un pipeline « classique » à 5 étages sont les suivantes :
Les instructions sont organisées en file d'attente dans la mémoire, et sont chargées les unes après les autres. Grâce au pipeline, le traitement des instructions nécessite au maximum les cinq étapes précédentes. Dans la mesure où l'ordre de ces étapes est invariable (LI, DI, EX, MEM et ER), il est possible de créer dans le processeur un certain nombre de circuits spécialisés pour chacune de ces phases. L'objectif du pipeline est d'être capable de réaliser chaque étape en parallèle avec les étape amont et aval, c'est-à-dire de pouvoir lire une instruction (LI) lorsque la précédente est en cours de décodage (DI), que celle d'avant est en cours d'exécution (EX), que celle située encore précédemment accède à la mémoire (MEM) et enfin que la première de la série est déjè en cours d'écriture dans les registres (ER).
Il faut compter en général 1 à 2 cycles d'horloge (rarement plus) pour chaque phase du pipeline, soit 10 cycles d'horloge maximum par instruction. Pour deux instructions, 12 cycles d'horloge maximum seront nécessaires (10+2=12 au lieu de 10*2=20), car la précédente instruction était déjà dans le pipeline. Les deux instructions sont donc en traitement dans le processeur, avec un décalage d'un ou deux cycles d'horloge). Pour 3 instructions, 14 cycles d'horloge seront ainsi nécessaires, etc. Le principe du pipeline est ainsi comparable avec une chaîne de production de voitures. La voiture passe d'un poste de travail à un autre en suivant la chaîne de montage et sort complètement assemblée à la sortie du bâtiment. Pour bien comprendre le principe, il est nécessaire de regarder la chaîne dans son ensemble, et non pas véhicule par véhicule. Il faut ainsi 3 heures pour faire une voiture, mais pourtant une voiture est produite toute les minutes ! Il faut noter toutefois qu'il existe différents types de pipelines, de 2 à 40 étages, mais le principe reste le même.
La technologie superscalaire (en anglais superscaling) consiste à disposer plusieurs unités de traitement en parallèle afin de pouvoir traiter plusieurs instructions par cycle.
La technologie HyperThreading (ou Hyper-Threading, noté HT, traduisez HyperFlots ou HyperFlux) consiste à définir deux processeurs logiques au sein d'un processeur physique. Ainsi, le système reconnaît deux processeurs physiques et se comporte en système multitâche en envoyant deux thréads simultanés, on parle alors de SMT (Simultaneous Multi Threading). Cette « supercherie » permet d'utiliser au mieux les ressources du processeur en garantissant que des données lui sont envoyées en masse.


| |||||||||||||||||||||||||
|
Ce document intitulé « Ordinateur - Le processeur » issu de Comment Ça Marche est mis à disposition sous les termes de la licence Creative Commons. Vous pouvez copier, modifier des copies de cette page, dans les conditions fixées par la licence, tant que cette note apparaît clairement. |